AI4EOSC LLM¶
As part of the tool repertoire that the platform is offering to increase our user’s productivity, we are current offering an LLM Chatbot service that allows users to summarize information, get code recommendations, ask questions about the documentation, etc.
We care about user privacy, so it’s important to notice that your chat history will be erased whenever you delete it, and no data will be retained by the platform (privacy policy).
Requirements
🔓 You need a platform account with basic access level.
🤔 Platform LLM vs self-deployed LLM
We also offer a self-deployed LLM option, so which one should you choose?
Self-deployed LLM
available to full access level users
let’s you deploy a wide variety of models from a catalog,
resources are exclusively dedicated to you and your selected coworkers,
you are the admin, so you can configure model and UI parameters,
you are the admin, so you can create your own Knowledge Bases as persistent memory banks,
you are the admin, so you can use Functions to create your own agents that use custom prompts, custom Knowledge Bases, and custom input/output filtering,
Platform LLM
available to all users (basic access level and above)
uses more powerful GPUs, so it offers bigger and more accurate LLMs,
zero configuration needed, access directly with your credentials,
the backend (VLLM) is load balanced so it can offer lower latency,
comes with some pre-configured helpful agents, like the Assistant that helps you navigate the project’s documentation,
By default, we recommend using the platform LLM, which will offer a better experience for most users. Users with more custom needs should try nevertheless the self-deployment options.
Anyway, remember that both options are compatible: you can deploy your own LLM and still access the platform-wide one. The best of both worlds! 🚀
Both options offer a privacy-first design: once your delete your chats or knowledge bases, the data is immediately wiped out from the platform.
Login¶
Login into: https://chat.cloud.ai4eosc.eu

Once you login, you will arrive to a landing page where you will be able to select the model which you want to interact with.
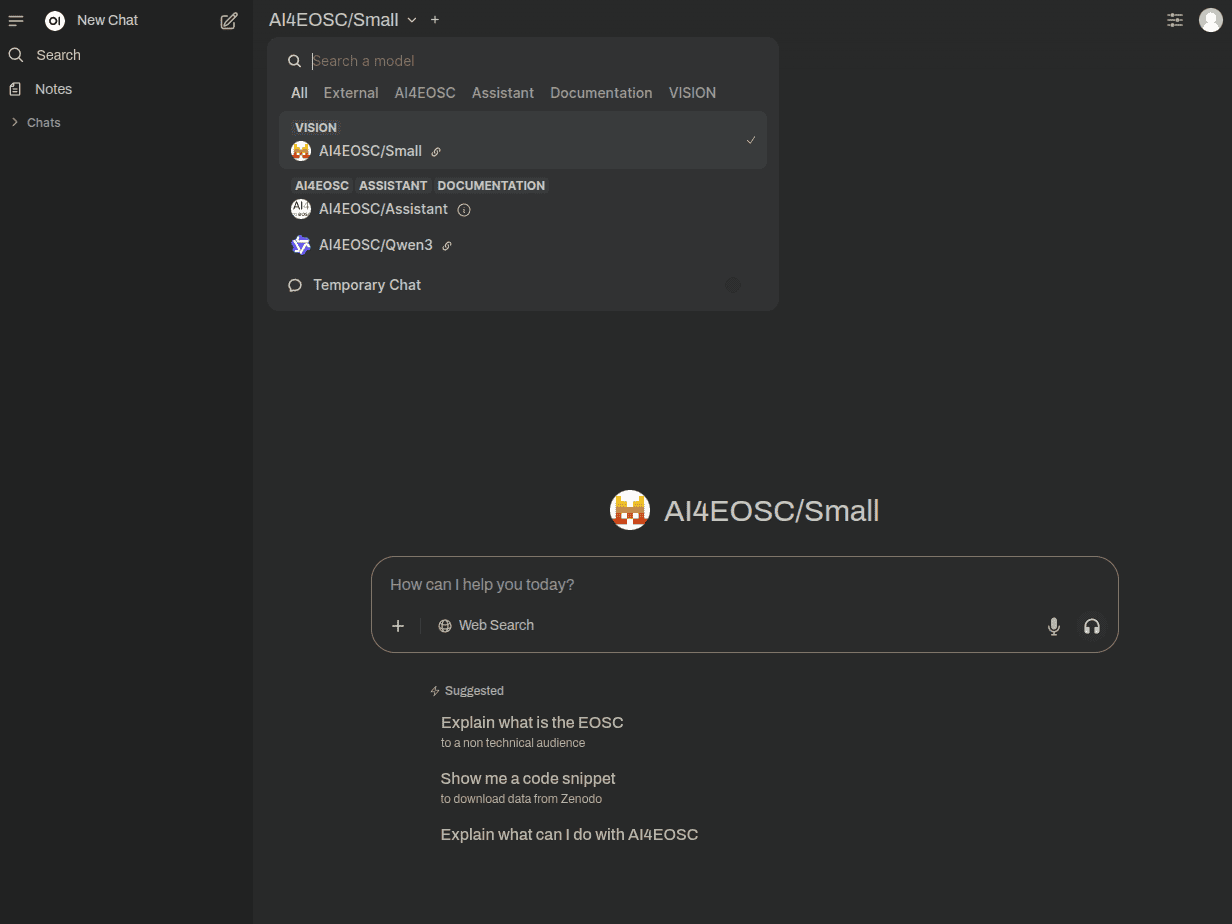
Available models might evolve, as we are constantly deploying newer, better and more efficient models. We typically server open-source/open-weights models from the Mistral family and the Qwen family. We also create custom agents, like the AI4EOSC Assistant that allows you to ask questions to our documentation.
Using the LLM¶
The AI4EOSC LLM interface is based on OpenWebUI, so please refer to the OpenWebUI documentation on how to use the different interface features (like the chat, the notes, the settings, etc).
In the following sections, we will briefly explain some common usage patterns.
Chat with the LLM¶
We can ask generic questions to the model.

Remember that if you answer relies on up-to-date information, you can always enable Web search under the button.
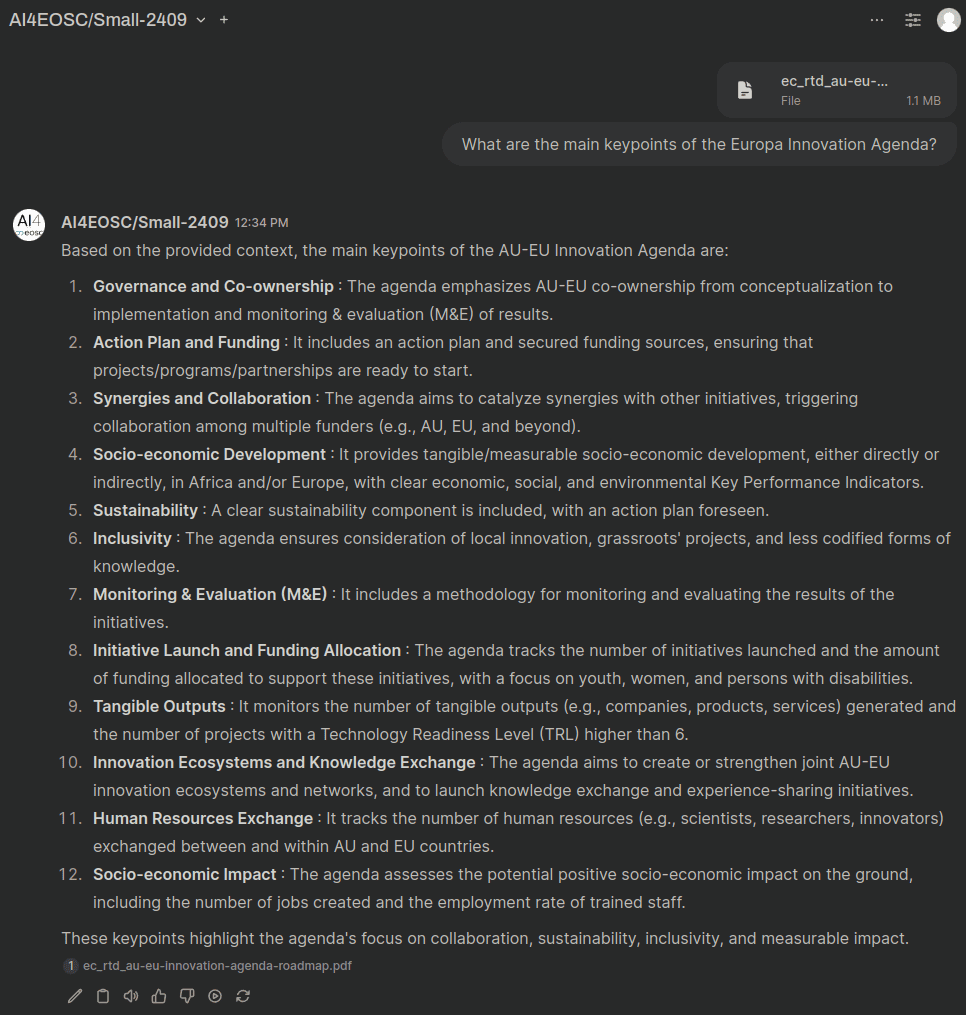
Summarize a document¶
Under the button, you can select Upload files.
This will allow you to query a document with questions.
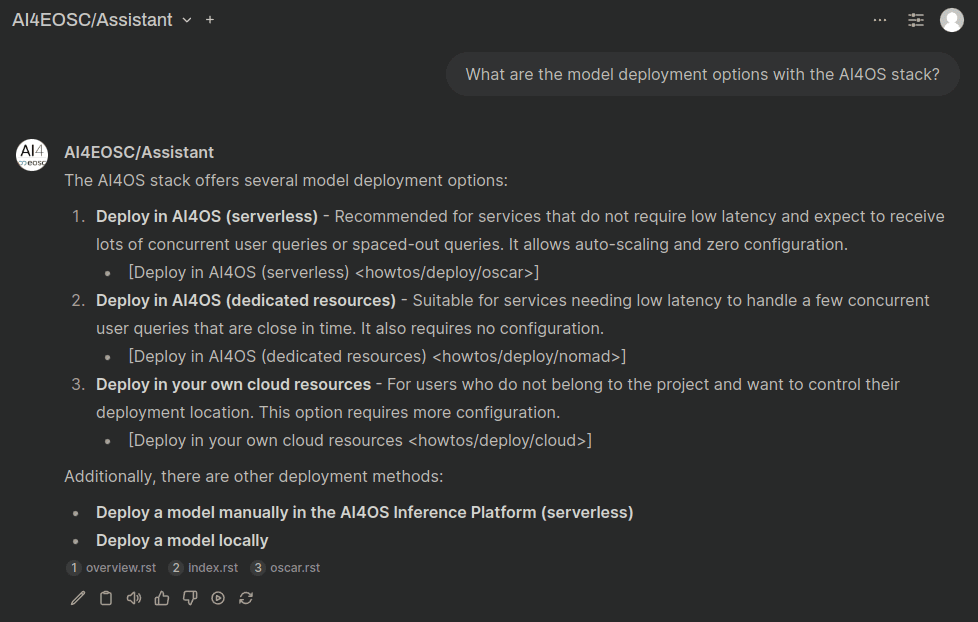
Ask questions about the documentation¶
In the upper left corner, you can select the AI4EOSC/Assistant model to ask questions about the platform. The LLM with use our documentation as knowledge base to provide truthful answers to your questions.
Use Vision models¶
In the model menu, select any model with the VISION tag. Then you will be able to upload images to the model and ask questions about them.
To upload an image click the and you will be offered the possibility of either Capture an image or Upload an image.
Here are some ideas on how to incorporate this into a scientific workflow:
Detexify a LaTeX equation
Generate latex code for the above picture and render it below.

Digitize your handwritten notes
Can you generate a Mermaid graph from this sketch? To ensure valid code, make sure that text inside boxes follows the format `letter{…}`. For example `B{Some text}`.

Do you use it in other ways? We are happy to hear!
Integrate it with your own services¶
You can access the LLM models via an OpenAI-compatible API for an easier integration with your own services.
Requirements
🔓 You need a platform account with intermediate access level or above.
Retrieve the API endpoint/key¶
The API endpoint to query the models is:
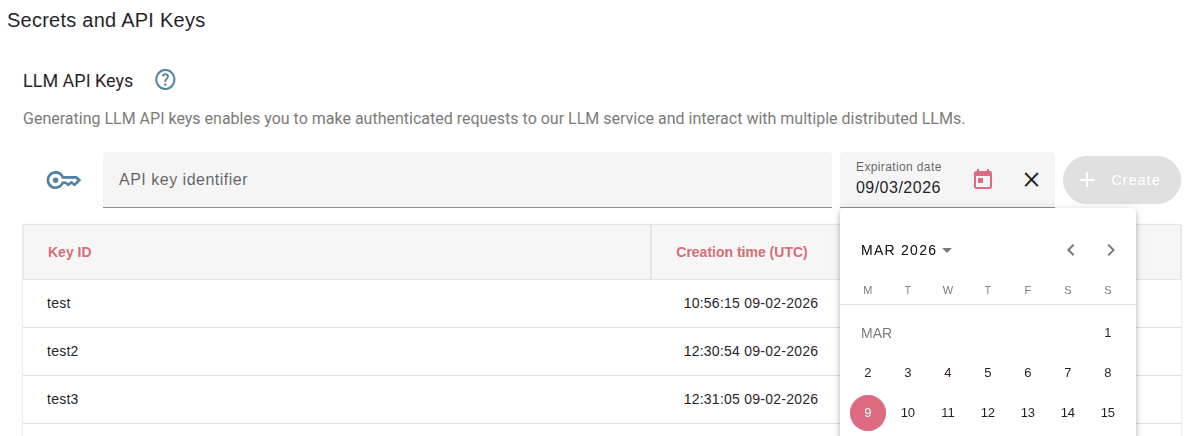
To generate the API keys go to the Dashboard profile, to the Secrets and API keys section.
There you will be able to create a new API key selecting the name and the expiration date.
ㅤ ℹ️ Budgets and rate limits
Each time you use an API key you will be consuming your daily budget. When you consume all your budget you will no longer be able to make further requests. After each day, your budget will be reset and you will be able to make calls again.
If you create different keys, both keys will consume the same budget.
Your budget depends on your current user access level.
(TPM = Tokens Per Minute, RPM = Requests Per Minute)
Group |
Budget (credits) / day / user |
TPM Limit / user |
RPM Limit / user |
|---|---|---|---|
ap-a |
0.05 |
1000 |
2 |
ap-a1 |
0.075 |
1500 |
2 |
ap-b |
0.1 |
2000 |
2 |
ap-u |
1 |
20000 |
20 |
ap-d |
1.5 |
30000 |
30 |
Each model will consume a different amount of resources. As a general rule of thumb:
small models (like Smol or OLMo) consume around
1e-8per input token and2e-8per output token.large models (like Mistral Small or Qwen 3) consume around
1e-7per input token and3e-7per output token.embedding models (like Qwen3 Embeddings) consume around
2e-8per input token.
You can use OpenAI tokenizer to get a rough estimate of how a given text maps into tokens.
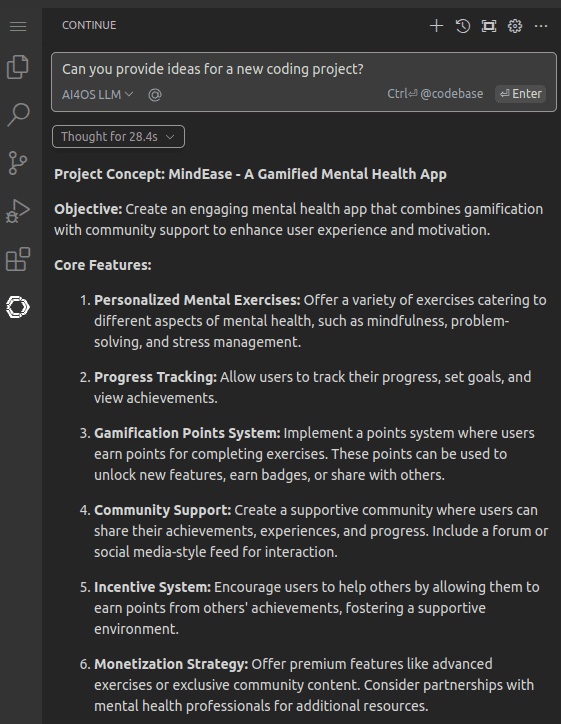
Use it as a code assistant with VScode¶
It’s very easy to use the LLM as a code assistant, both locally and in the Development Environment. To configure it:
In VScode, install the Continue.dev extension.
Open the Continue config file:
/home/<user>/.continue/config.yamlModify it to add the LLM model, using your API key:
models: - name: AI4EOSC LLM provider: openai model: AI4EOSC/mistralai/Mistral-Small-3.1-24B-Instruct-2503 apiKey: "sk-************************************" apiBase: https://vllm.cloud.ai4eosc.eu/ roles: - chat - edit - apply
Voilá, you are done! Check the Continue short tutorial for a quick overview on how to use it.
Use it from within your Python code¶
To use the LLM from your Python scripts you need to install the openai Python package. Then you can use the LLM as following:
from openai import OpenAI
client = OpenAI(
base_url="https://vllm.cloud.ai4eosc.eu",
api_key="sk-************************************",
)
completion = client.chat.completions.create(
model="AI4EOSC/mistralai/Mistral-Small-3.1-24B-Instruct-2503",
messages=[{"role": "user", "content": "What is the capital of France?"}]
)
print(completion.choices[0].message.content)
ㅤ ⚠️ Query token limit
The models served have a typical token limit per call. If your query exceeds this token limit, you will get an error message similar to:
BadRequestError: Error code: 400 - {'object': 'error', 'message': 'max_tokens must be at least 1, got -30979.', 'type': 'BadRequestError', 'param': None, 'code': 400}
Implement a RAG pipeline¶
We also have a dedicated embeddings model that let’s you perform Retrieval Augmented Generation (RAG). This allows the model to ground its answers on the specific documents you pass to it. You can implement a RAG pipeline using the llama-index Python package, for example.
After installing the required packages,
pip install llama-index
pip install llama-index-llms-openai-like
pip install llama-index-embeddings-openai-like
define your demo pipeline:
from llama_index.core import Settings, VectorStoreIndex, Document, SimpleDirectoryReader
from llama_index.llms.openai_like import OpenAILike
from llama_index.embeddings.openai_like import OpenAILikeEmbedding
Settings.embed_model = OpenAILikeEmbedding(
api_base="https://vllm.cloud.ai4eosc.eu",
api_key="sk-************************************",
model_name="AI4EOSC/Qwen/Qwen3-Embedding-4B",
)
Settings.llm = OpenAILike(
api_base="https://vllm.cloud.ai4eosc.eu",
api_key="sk-************************************",
model="AI4EOSC/mistralai/Mistral-Small-3.1-24B-Instruct-2503",
context_window=25000,
is_chat_model=True,
is_function_calling_model=False,
)
# Simple document example 📄️
text_to_embed = "My favorite fruit are apples."
documents = [Document(text=text_to_embed)]
# But you can also load entire document folders 📂️
# documents = SimpleDirectoryReader(input_dir="/path/to/your/document/folder").load_data()
# Build index and query engine
index = VectorStoreIndex.from_documents(documents)
query_engine = index.as_query_engine()
# Ask the LLM a question
response = query_engine.query("What is my favorite fruit?")
print(response)
# > Apples are your favorite fruit.